ReGrade 3: Every Merge Request Gets a Behavioral Audit — Automatically
Your CI pipeline catches syntax errors and failing tests. It does not tell you what actually changed in your API behavior. ReGrade 3 drops into your GitLab or GitHub pipeline and posts field-level behavioral regression reports directly in your merge request comments — giving developers, QA, and security teams the analysis they need before code hits main.
Drop ReGrade into your CI pipeline and every merge request gets a field-level behavioral regression report — before code hits main.
Your CI pipeline runs unit tests. It runs linters. It runs static analysis. If you’re thorough, it runs integration tests against a staging environment. All of these answer the same question: does the code meet the expectations we’ve written down?
None of them answer the question that actually matters: did anything change that we didn’t expect?
That’s the question ReGrade 3 answers — automatically, on every merge request, posted directly in the MR comments where your developers, QA engineers, and security team are already looking.
The Regression Testing Problem
Regression testing is one of the most expensive activities in software development. Software maintenance itself exceeds 70% of total software costs, and regression testing constitutes a massive share of that maintenance budget. The widely cited figure — roughly 80% of testing effort goes to regression — has been validated across three decades of research starting with Leung and White’s 1989 IEEE study.
And despite that investment, most of what regression suites catch isn’t real.
Google’s testing infrastructure data reveals that almost 16% of their tests exhibit some level of flakiness. While only about 1.5% of all test runs report a flaky result, an extraordinary 84% of observed pass-to-fail transitions in post-submit testing involve a flaky test — not a real bug. Only 1.23% of test executions actually found a real breakage.
Slack Engineering reported that before automated flaky test handling, their main branch stability sat at roughly 20% pass rate, with 57% of build failures caused by test job failures. Each failure took about 28 minutes to manually triage. The most rigorous empirical study on CI test failures — Labuschagne, Inozemtseva, and Holmes examining 61 Java projects on Travis CI — found that of non-flaky test failures, only 74% were caused by actual bugs in the system under test. The remaining 26% were due to incorrect or obsolete tests. Pure maintenance cost.
The pattern is clear: teams spend enormous resources running regression suites, and most of the signal is noise. Meanwhile, the real behavioral changes — the ones that break downstream consumers, leak data, or subtly alter API contracts — slip through because no test was written to look for them.
Code Review Can’t Scale to AI-Speed Development
The traditional safety net after testing is code review. But code review is buckling under the weight of AI-generated code volume.
The landmark SmartBear/Cisco study — 2,500 reviews across 3.2 million lines of code — established that review effectiveness peaks at 200–400 lines and should last no more than 60–90 minutes. Microsoft Research found that reviewers spend 6 minutes per file for small PRs but only 1.5 minutes per file for PRs over 20 files — a 4× reduction in attention per file.
Now layer AI-generated code volume on top. GitHub’s Octoverse 2025 report documents 43.2 million PRs merged per month — a 23% year-over-year increase. The Faros AI study found that high-AI-adoption teams merge 98% more PRs while PR sizes grow 154%. Median PR size increased 33% industry-wide in 2025. Reviewers face roughly 5× the total code volume they did two years ago.
Microsoft Research itself published a paper titled “Code Reviews Do Not Find Bugs,” arguing that the primary value of review is knowledge transfer and code comprehension, not defect detection. Steve McConnell’s meta-analysis confirms that informal code review catches only 20–35% of defects. When PRs are larger and reviewers are more fatigued, that number drops further.
Your pipeline needs something that doesn’t get tired, doesn’t lose attention after 400 lines, and doesn’t need someone to have written an assertion for every possible behavioral change.
What ReGrade 3 Does in Your Pipeline
ReGrade integrates into your GitLab or GitHub CI pipeline as a step that runs on every merge request. Here’s the mechanism:
Record your baseline. ReGrade captures real API traffic against your current trusted version — main branch, production, whatever you designate as the source of truth. Login flows, CRUD operations, authentication, data retrieval — every request and response, recorded at the packet level.
Replay on every MR. When a developer opens a merge request, the pipeline replays the recorded traffic against the candidate version. Same requests, new target.
Compare field by field. ReGrade’s NCAST engine compares every response between baseline and candidate. Not just status codes — every field, every header, every value. Dynamic content like timestamps, session tokens, and auto-generated IDs get classified as expected noise through configurable ID mapping and filter rules.
Report in the MR comments. What remains after noise filtering are the real findings — behavioral changes that aren’t accounted for. ReGrade posts these directly in the merge request as structured comments, with the exact field path, the baseline value, and the candidate value.
No test scripts to write. No mocks to maintain. No SDK to install. The entire system runs in a container under 25MB and handles encrypted traffic via TLS proxying.
What It Looks Like
In our CVE-2023-5968 case study, we ran 22 standard API tests against a collaboration platform. 287 requests. Raw replay produced 3,730 deltas. After configuring 5 ID mapping namespaces and 12 filter rules, 3,728 of those deltas were classified as expected noise.
What remained: 2 security findings. Both showing bcrypt password hashes in API response bodies — a vulnerability that had survived 7 years of unit tests, integration tests, code reviews, and security audits.
ReGrade merge request comments showing security findings:
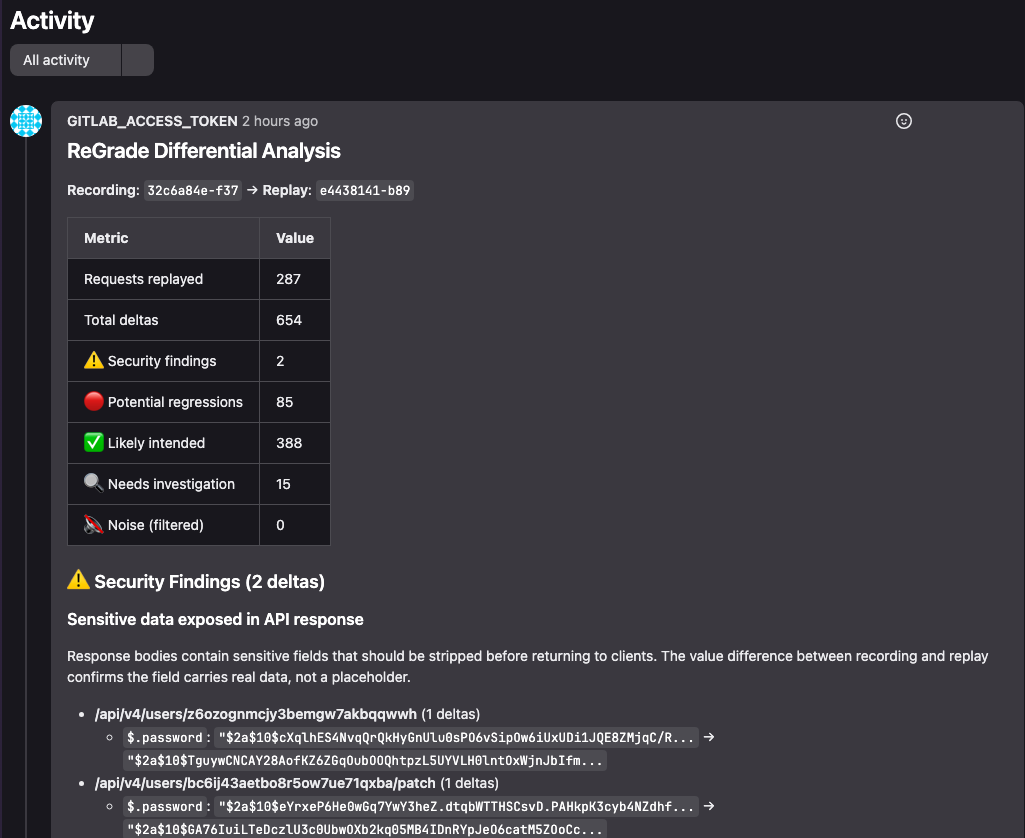
ReGrade’s merge request comment flagging 2 security findings — bcrypt password hashes in API response bodies.
Every pipeline had passed. Every code review had approved. The vulnerability was structurally invisible to any tool that validates expectations. ReGrade caught it on the first replay because fresh server instances generate different bcrypt salts — the entropy itself was the detection mechanism.
Three Audiences, One Report
ReGrade’s MR comments serve three distinct audiences that all converge on the merge request:
Developers see exactly what their changes did to API behavior. Not what tests say should happen — what actually happened. If a refactor subtly changed a response field name, or a dependency upgrade altered header behavior, or a new code path returns data it shouldn’t, it shows up in the diff. This catches the class of bugs that developers describe as “it worked on my machine” — because ReGrade compares behavior across real server instances, not local test environments.
QA engineers get a behavioral regression report without writing a single test case. Every API call in the recorded traffic is effectively a test case. The noise profile — ID mappings, timestamp filters, session token exclusions — is configured once and refined over time, not rewritten per sprint. QA shifts from authoring and maintaining regression suites to reviewing behavioral diffs and classifying findings.
Security teams get automated detection of data exposure, authentication anomalies, and response structure changes that indicate potential vulnerabilities. The CVE-2023-5968 finding is the canonical example: a password hash disclosure that no security scanner, no penetration test, and no code review caught in seven years. ReGrade caught it because it doesn’t look for known vulnerabilities — it surfaces unknown behavioral differences.
No More Merging Blind
The current state of CI/CD testing asks a narrow question: do the tests we wrote still pass? If you’ve written good tests and kept them current, you get partial coverage. If your tests are flaky — and at Google’s scale, 16% of them are — you get noise. If the behavioral change is something nobody anticipated, you get nothing.
ReGrade asks a different question: did anything actually change? And it gives you a definitive, deterministic answer on every merge request — in the comments, where the conversation is already happening, before code hits main.
Bugs found in production cost 15× to 100× more to fix than bugs found during development, depending on whose research you cite (Boehm’s 1981 data from IBM and TRW projects, validated by NIST’s 2002 estimate of $59.5 billion in annual US costs from inadequate software testing infrastructure). The cheapest place to find a behavioral regression is in the merge request — and that’s exactly where ReGrade puts it.
Try ReGrade 3 free today at curtail.com.
Sources
- Leung & White, “Insights into Regression Testing” (IEEE, 1989) — Foundational regression testing cost research.
- Google Testing Blog (John Micco), “Flaky Tests at Google and How We Mitigate Them” (2016) — 16% test flakiness, 84% of pass-to-fail transitions flaky. testing.googleblog.com
- Google Research, “Taming Google-Scale Continuous Testing” (2017) — 1.23% of test executions find real breakages. research.google.com
- Slack Engineering, “Handling Flaky Tests at Scale” (2022) — 20% main branch pass rate, 57% failures from test jobs. slack.engineering
- Labuschagne, Inozemtseva, Holmes (ESEC/FSE 2017) — 61 Java projects, 74% of non-flaky failures are real bugs, 26% test maintenance. dl.acm.org
- SmartBear/Cisco Code Review Study (2006) — 2,500 reviews, 3.2M lines, optimal 200–400 LOC. smartbear.com
- Microsoft Research (Bosu et al.) — Review attention drops 4× on large PRs. microsoft.com
- Microsoft Research (Czerwonka et al.), “Code Reviews Do Not Find Bugs” — microsoft.com
- GitHub Octoverse 2025 — 43.2M PRs/month, 23% YoY increase. github.blog
- Faros AI Productivity Study (June 2025) — 98% more PRs merged, 154% larger, 91% longer review. faros.ai
- NIST Planning Report 02-3 (2002) — $59.5B annual US cost from software bugs. nist.gov
- Boehm, “Software Engineering Economics” (1981) — Cost escalation curve for late-stage bug detection.
- Curtail, “How We Found a 7-Year-Old Vulnerability — On the First Replay” — CVE-2023-5968 case study. curtail.com